How to Scrape Data From Twitter Profile Pages

Update: 1/8/2019
Twitter has updated their layout to render data primarily through Javascript. You will need to scrape https://mobile.twitter.com rather than https://twitter.com. As mobile twitter still renders html in the source. We will be updating the scraper soon to be able to crawl js rendered content.
I have been meaning to write this blog post for a while. Mainly because it is a frequent support query, and it would be easier to have a proper article to point people to than constantly re-write the same answers (and I am lazy).
If my support tickets are anything to go by, a lot of people want to be able to fetch data about Twitter accounts like their number of tweets or followers.
This post will explain how to do all of these things, and more.
#1 Build a List of Twitter Profile URLs
URL Profiler is probably the most unimaginatively named tools on the planet. It builds up a profile…of a URL.
This means you need to ‘feed’ it with URLs to actually use it.
In the case of scraping data from Twitter, the URLs in question need to be the URLs where the data is publicly displayed, namely, Twitter profile pages.
- https://twitter.com/urlprofiler
- https://twitter.com/HathawayP
- https://twitter.com/gareth_brown
That sort of jazz.
If you don’t already know the profile links, but DO know the website, you are in luck, my friend, because URL Profiler can go and grab them for you.
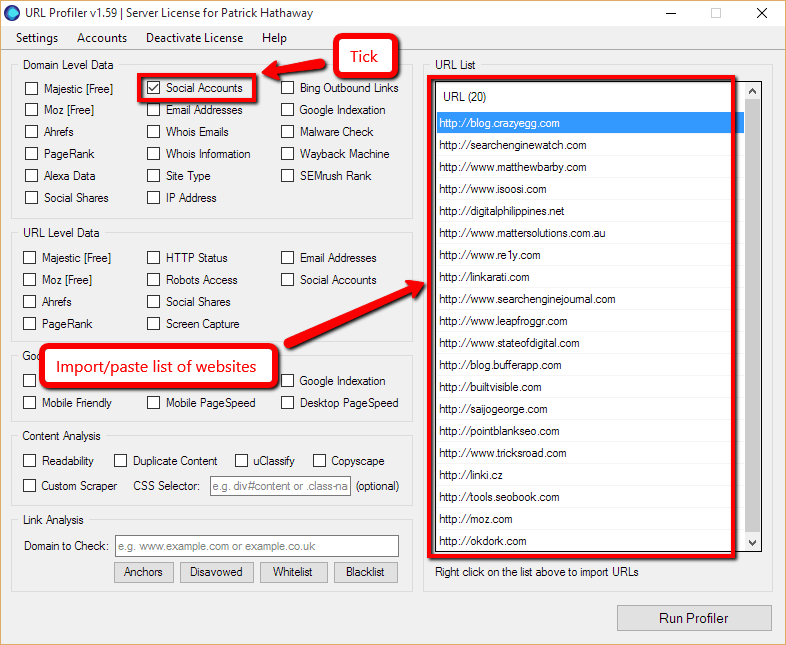
As per the image above (click to enlarge), import your list of website addresses into the white box on the right, then click ‘Social Accounts’ under ‘Domain Level Data’.
URL Profiler will go and check common pages on those websites and try to extract all the social profile links it can find (including Twitter, obvs). It won’t always be able to find everything – it isn’t perfect – but it’s a damn sight quicker than visiting all the pages manually.
Aside: In addition to the method above to scrape social profiles, I have written 2 further posts about collecting Twitter data:
- Outreach Influencers Directly Using Twitter Custom Audiences – this contains a number of manual methods of finding Twitter profile links.
- Scraping Twitter Lists To Boost Social Outreach – explains how to scrape Twitter lists to get all the profile pages of the list members.
Note: If you don’t even know the website URL, then you’re fucked. In fact I don’t really know why you’re reading this article.
#2 Fire Up The Custom Scraper
URL Profiler has a number of built-in features that allow you to scrape common data from webpages, including:
- Social Account URLs (as above)
- Email Addresses
- Page Titles and Descriptions (cunningly hidden in the ‘Readability’ option)
We have a lot of customers using this data to build prospecting lists, and occasionally we find that they need more data than we give them out the box.
Luckily, we have a tool to help these fine individuals, called the ‘Custom Scraper’. This allows you to specify particular datapoints from a specific webpage, load in thousands of URLs, and scrape the lot of ’em!
Where this comes in most useful is when you want to scrape structured data from a lot of similar webpages. Directories are a good example, as their listings pages are always set up the same. So from the example below, we could set up the tool to scrape the company name, or their telephone number, address etc…

Fortunately (due to the topic of this post), Twitter profile pages are also nicely structured, meaning we can use the Custom Scraper to extract the data we need.
If you can’t find the custom scraper, you are probably looking in the wrong place. It’s…
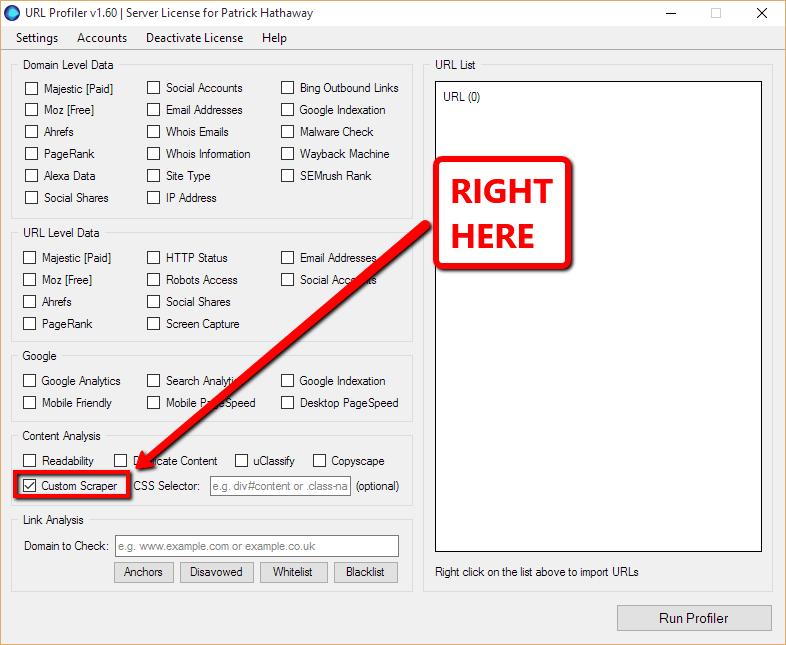
The custom scraper works by allowing you to identify parts of a webpage that you wish to scrape, using selectors. Once you tick the box above, the Custom Scraper configuration menu appears, consisting of 4 elements you need to define.
The rows along the left allow you to define 10 different datapoints you might want to scrape from a single page. The columns running left to right determine ‘how you tell the tool which bits you want to scrape.’
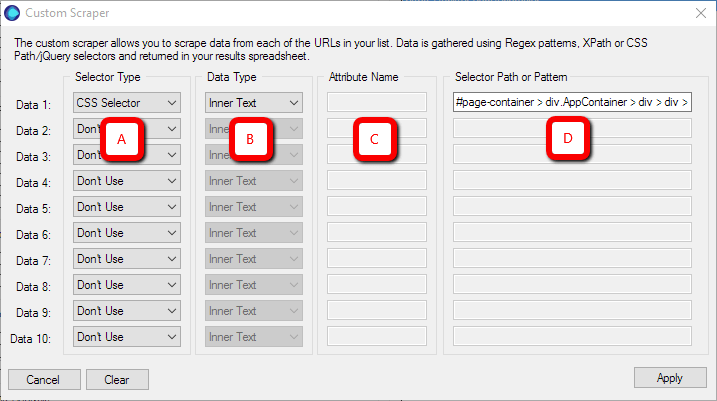
- Selector Type (A): Choose from a dropdown of CSS Selector, XPath Selector, Regex Pattern. I tend to normally try CSS Selector first.
- Data Type (B): Choose from Inner Text, Inner HTML, or Attribute. Inner Text is usually appropriate if you want to pull back what you see on screen. Inner HTML if you want to extract the HTML for a particular element. Attribute will make use of specific semantic markup (e.g. ‘href’ will pull back the target URL of a link).
- Attribute Name (C): This option only applies if you chose ‘Attribute’ from column B. You need to enter the attribute which uniquely identifies the content you wish to scrape within the selected area (e.g. ‘href’ or ‘title’).
- Selector Path or Pattern (D): Probably the most important bit, this tells the tool where on the page it needs to look. So in the example above, we have defined a specific CSS path where the content lives.
This may all sound really complicated, but I promise you it’s not. I am not a developer (not even close – I managed to bloody well break WordPress the other day), but I can normally scrape anything I need to. There is one core technique you will need to learn (examples coming up below), plus a willingness to persevere and experiment.
#3 Scraping Twitter Profile Pages
In this section we are going to need a big list of URLs of the form:
And from these I’ll show you how we can scrape pretty much any datapoint from each page.
So, this is the sort of page we are looking at:
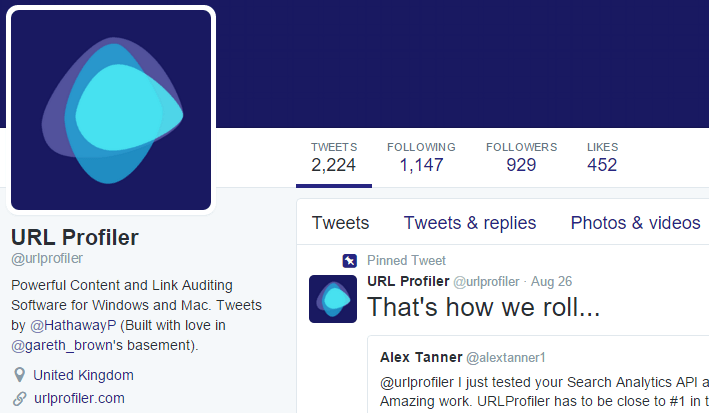
Anything ‘permanent’ can be scraped, so we’re talking:
- Name and username
- Description
- Location
- Web Address
- Tweets/Following/Followers/Likes
How to Scrape Twitter
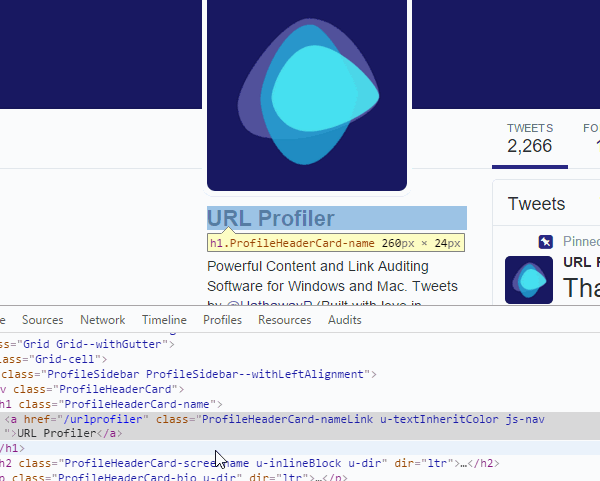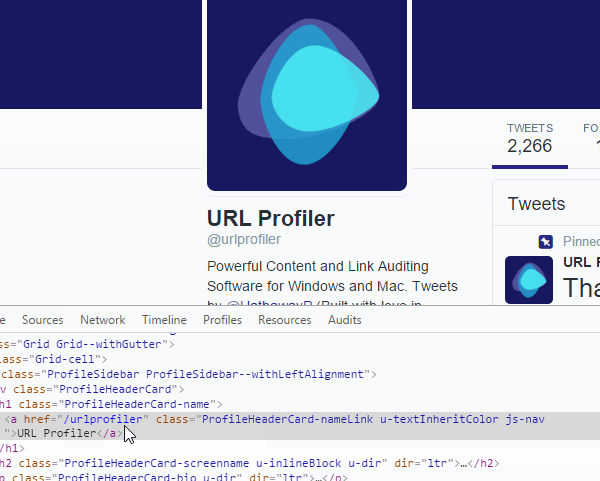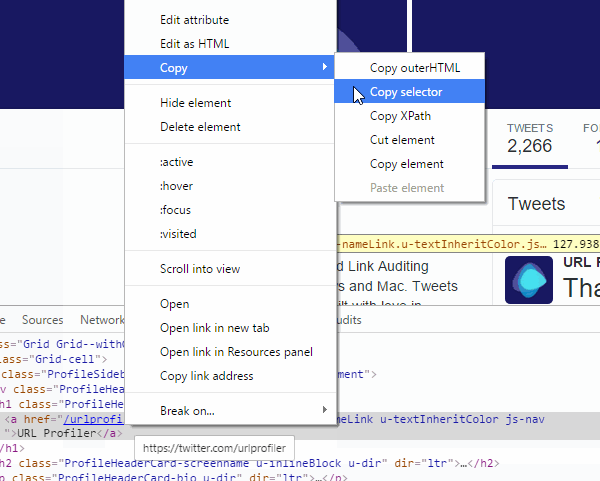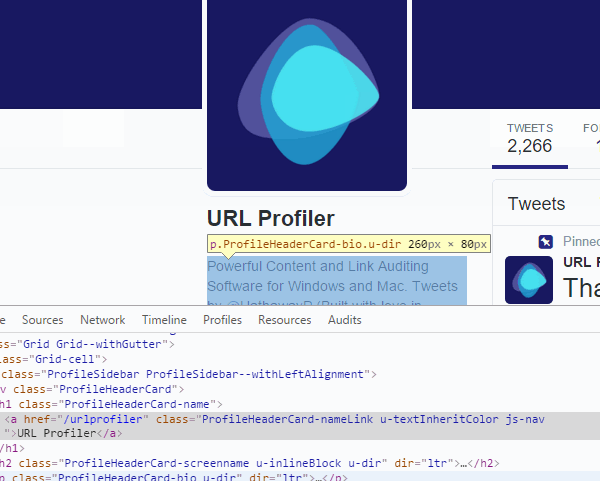
Here’s the one technique you need: Inspect Element in Google Chrome (although they seem to have recently renamed it to ‘Inspect’).
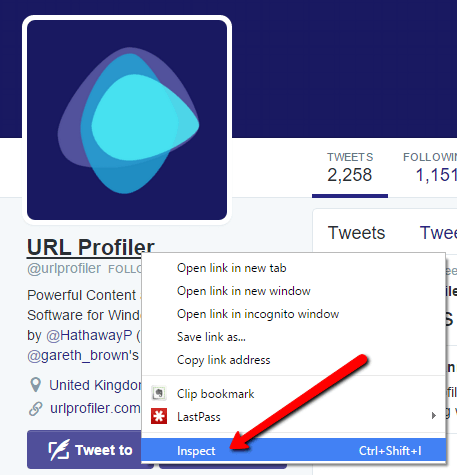
To do this, you need to right click on the element you wish to scrape (in this case I clicked on the name), then choose ‘Inspect’.
This will bring up the Console at the bottom of the screen, and highlighted in a uselessly dull grey will be the element you right clicked on.
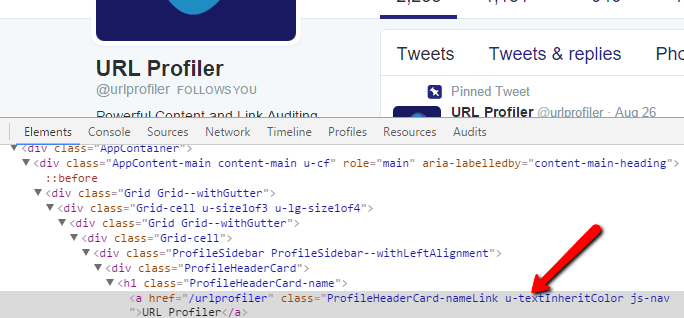
Then, right click somewhere on the grey, so that it turns into a nice vivid blue (royal blue, perhaps?). Hover over ‘Copy’ so the contextual menu pops out, then choose ‘Copy selector’ from the dropdown.
If you’re following along at home, this will look like:
#page-container > div.AppContainer > div > div > div.Grid-cell.u-size1of3.u-lg-size1of4 > div > div > div > div.ProfileHeaderCard > h1 > a
And this is our selector path. This is what we need to paste into the Custom Scraper column Selector Path or Pattern (D).
In fact, to scrape this element we need the exact configuration I used on the screenshot earlier. For clarity, this would be:
- Selector Type (A): CSS Selector.
- Data Type (B): Inner Text.
- Attribute Name (C): N/A (blank).
- Selector Path or Pattern (D): As per grey box above.
When I am setting up a new custom scrape, I tend to build my scraper definitions first just using a single URL. Then validate it works ok on that URL, and then on maybe 5-10 more, before letting it loose on thousands of URLs at once.
So, we’ll run our first rule on URL Profiler’s Twitter page (feel free to follow, they share some fucking awesome shit y’know).

Scroll across to the right, and we’ll see the correct data in the column ‘Data 1’. Bada bing, bada bong.
Scraping Twitter Followers (and all that jazz)
So far I’ve just shown you how to scrape a single element from a page. Where that becomes powerful is if you load in 20,000 Twitter profile URLs, giving you 20,000 pieces of data instead of 1.
Where that becomes even more powerful is if you define another 9 elements to scrape off every page: 200,000 datapoints – that’s a shit ton of data.
I’m going to move a bit quicker now, so if you find yourself getting stuck, revisit the steps in the example above.
Scrape: Twitter Username
As before, right click on the element in the webpage, to bring up the console. It should look like this:

Again, Right Click -> Copy > Copy Selector
#page-container > div.AppContainer > div > div > div.Grid-cell.u-size1of3.u-lg-size1of4 > div > div > div > div.ProfileHeaderCard > h2 > a > span
We need the same options as last time for A (CSS Selector) and B (Inner Text).
Run it to test:
![]()
Bingo.
Scrape: Twitter Description
Same as last time, right click on the description and ‘Inspect’.

Again, Right Click -> Copy > Copy Selector
#page-container > div.AppContainer > div > div > div.Grid-cell.u-size1of3.u-lg-size1of4 > div > div > div > div.ProfileHeaderCard > p
We need the same options as last time for A (CSS Selector) and B (Inner Text).
Run it to test:
![]()
We’re well and truly cooking with gas now.
Location/Tweets/Following/Followers/Likes
You literally rinse/repeat this exact same formula to get the other selectors. So everything stays as the same for A (CSS Selector) and B (Inner Text). Then our selectors (C), will be the following:
Scrape: Twitter Location
#page-container > div.AppContainer > div > div > div.Grid-cell.u-size1of3.u-lg-size1of4 > div > div > div > div.ProfileHeaderCard > div.ProfileHeaderCard-location > span.ProfileHeaderCard-locationText.u-dir
Scrape: Tweet Count
#page-container > div.ProfileCanopy.ProfileCanopy--withNav.ProfileCanopy--large > div > div.ProfileCanopy-navBar > div > div > div.Grid-cell.u-size2of3.u-lg-size3of4 > div > div > ul > li.ProfileNav-item.ProfileNav-item--tweets.is-active > a > span.ProfileNav-value
Scrape: Twitter Following
#page-container > div.ProfileCanopy.ProfileCanopy--withNav.ProfileCanopy--large > div > div.ProfileCanopy-navBar > div > div > div.Grid-cell.u-size2of3.u-lg-size3of4 > div > div > ul > li.ProfileNav-item.ProfileNav-item--following > a > span.ProfileNav-value
Scrape: Twitter Followers
#page-container > div.ProfileCanopy.ProfileCanopy--withNav.ProfileCanopy--large > div > div.ProfileCanopy-navBar > div > div > div.Grid-cell.u-size2of3.u-lg-size3of4 > div > div > ul > li.ProfileNav-item.ProfileNav-item--followers > a > span.ProfileNav-value
Scrape: Twitter Likes
#page-container > div.ProfileCanopy.ProfileCanopy--withNav.ProfileCanopy--large > div > div.ProfileCanopy-navBar > div > div > div.Grid-cell.u-size2of3.u-lg-size3of4 > div > div > ul > li.ProfileNav-item.ProfileNav-item--favorites > a > span.ProfileNav-value
And Now For Something Completely Slightly Different
Everything we’ve defined so far uses the Data Type (B) of ‘Inner Text.’ But now we want to grab the website URL, and for this we’ll need to use an Attribute instead. You’ll see why in this example below.
Scrape: Twitter Web Address
As before, we right click on the element we wish to scrape, this time the web address.
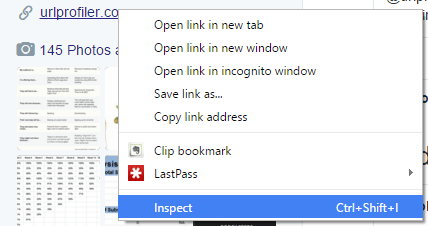

Now, if we scraped ‘Inner Text’ from this selection, we’d end up with ‘urlprofiler.com’, which is good but not necessarily what we want. To get the full URL, we normally advise that you scrape the href attribute. But notice that the actual href goes through a Twitter t.co wrapper, which again is good but not really what we want.
The actual URL is stored in the ‘title’ attribute, so that’s exactly what we need to write into the ‘Attribute’ box. We still do Right Click -> Copy > Copy Selector, to get:
#page-container > div.AppContainer > div > div > div.Grid-cell.u-size1of3.u-lg-size1of4 > div > div > div > div.ProfileHeaderCard > div.ProfileHeaderCard-url > span.ProfileHeaderCard-urlText.u-dir > a
So our configuration for the Custom Scraper becomes:
- Selector Type (A): CSS Selector.
- Data Type (B): Attribute
- Attribute Name (C): title
- Selector Path or Pattern (D): As per grey box above.
Bonus Invisible 10th Data Point
We’ve scraped pretty much all the useful visible data from our Twitter profile page. But earlier I was banging on about 10 data points yielding 200,000 results etc… so it would be a bit of a dick move on my part if I didn’t now show you a 10th item to scrape.
Scrape: Twitter User ID
You might want to use your Twitter User ID for building a custom audience list, or other less savoury operations perhaps…
I call this one ‘invisible’ because it’s not data that is visible on the page (and that’s sorta the definition of invisible, right?).
But it is visible in the HTML.
Browse around for a bit and soon you’ll see an ID number referenced in a number of places, using the attribute ‘data-user-id’ (try Ctrl+F if you can’t see it). Find one using Inspect, and proceed as previous.

So we’ll need to use an Attribute again, and of course we’ll need to copy the selector.
#page-container > div.ProfileCanopy.ProfileCanopy--withNav.ProfileCanopy--large > div > div.ProfileCanopy-navBar > div.AppContainer > div > div.Grid-cell.u-size2of3.u-lg-size3of4 > div > div
- Selector Type (A): CSS Selector.
- Data Type (B): Attribute
- Attribute Name (C): data-user-id
- Selector Path or Pattern (D): As per grey box above.
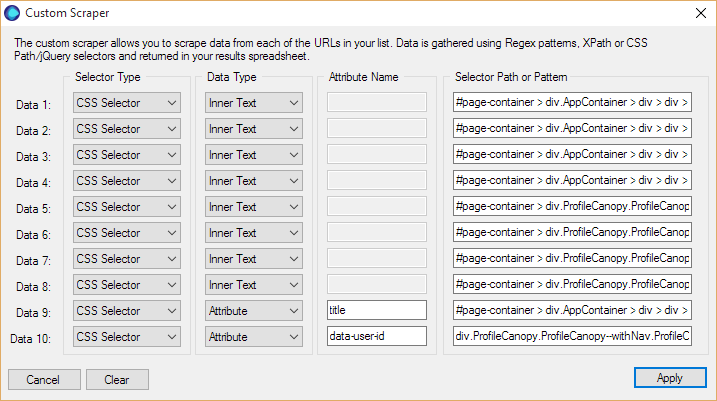
Custom Scraper Full Setup
If you’ve been building up your scraper config as we go, it should look something like this:
Testing Your Scraper
I have advocated checking along the way, and it is definitely worth testing your setup on a handful of URLs before moving onto a bigger list. In particular, this helps ensure that the selectors you have picked are common across all similar pages. If there are some unique elements in there, the scraper will only work for the single URL you copied your selectors from.
So paste a few Twitter Profile URLs into URL Profiler, and check you are getting the right data in all the fields (I added the proper column headings myself).
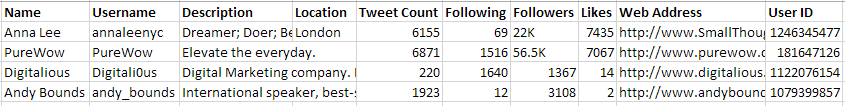
It is worth noting that some fields (like Location) won’t always be filled in, in which case the cells will just be empty.
Disclaimer(s)
The selectors I’ve used in this post for scraping Twitter elements work today. If you read this in a year’s time and they don’t work, that’ll be because Twitter changed something. I have tried to show you the methodology for building your own selectors, so you can re-do them if necessary.
Also, I don’t claim that the selectors I used are the most elegant options. There are almost definitely neater selectors that will capture the same data, and those more familiar with code might wish to point that out. But this post isn’t really aimed at you, it’s aimed at people who don’t know how or where to start with scraping, and this is a pretty fool-proof way in (I hope…).
Scaling Up
There is one more very important step, that I probably should have mentioned earlier. Twitter…erm, don’t really like you scraping their shit. In fact it’s against their Terms of Service.
So don’t do it. This was just a thought experiment….
…oh you’re still here? Well whilst I’ve got you, I might as well tell you that a part of ‘Twitter not wanting you to scrape their shit’ means that they will block you if they think you’re accessing their pages too quickly.
So we need to slow URL Profiler down a bit. Head to Settings-> Connections.
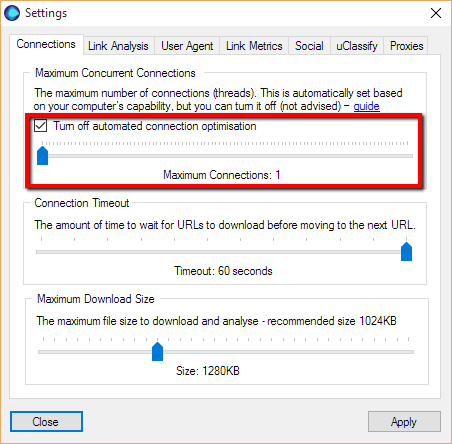
You need to tick the box marked ‘Turn off automated connection optimisation’ and ignore the warning. Slide the slider down to the left, so it says ‘Maximum Connections: 1.’
That should slow the requests down so you can pump a load of URLs in there and scrape the shit out of Twitter.
For completeness (and to conclude today’s thought experiment), you should end up with a wall of data not dissimilar to this:
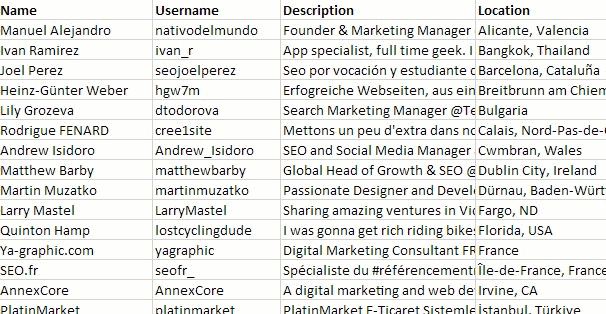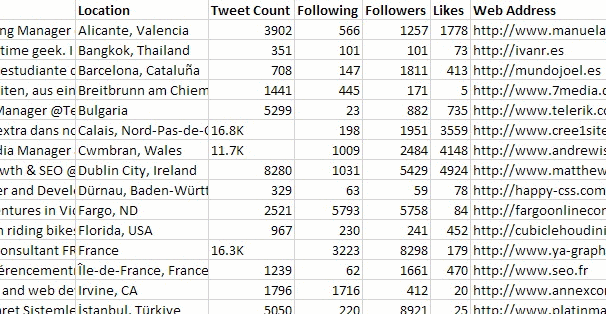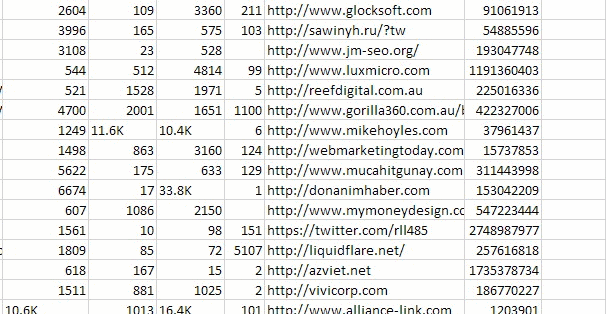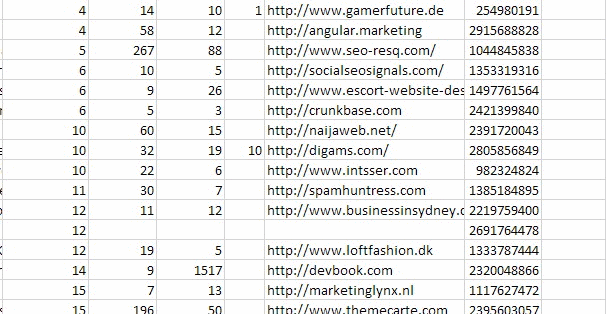
Although, seriously you guys, my recommendation is not to do this.

Now…Scrape Anything
Hopefully I’ve provided enough examples for you to get the gist of the core technique for copying selectors. It might take you a couple of goes to get it right, which is why I encourage testing on small sets of URLs. But once you get it, you can pretty much go off and scrape any website – you just follow the exact same steps.
Happy scraping!

By Patrick Hathaway
I seem to be the one that writes all the blog posts, so I am going to unofficially name myself 'Editor'. In fact, I think I prefer Editor-in-chief. You can follow me on Twitter or 'encircle me' on Google+.
If You Like the Sound of URL Profiler,
Download a Free Trial Today
(You'll be amazed by how much time it saves you, every day!)
- Free 14 day trial (full feature)
- No credit card required
- License from only £12.95 a month



