Scraping Twitter Lists To Boost Social Outreach (+ Free Tool!)

I published a post a few weeks ago describing how to build your own twitter custom audience list, outlining a variety of techniques to build up your list.
This post outlines another method (hat tip to Ade Lewis for the idea) which requires you to scrape Twitter directly.
If you want to skip all the explanations and just want to download the Twitter List Scraper tool, here you go…
Download the Twitter Scraper Tool for Windows or Mac (completely free)
Disclaimer: Scraping Twitter is against their Terms of Service, so if you decide to do this you do it at your own risk.
Some Benchmarks
Building custom audiences on Twitter requires you to identify Twitter usernames that might be interested in your service or product.
In my previous posts, one of the methods I employed was to pull a competitor’s link profile and scrape social accounts from the linking domains.
Once you upload a custom list, Twitter goes through a process of ‘matching’ against profiles in their system, to make sure the user exists and hasn’t opted out of tailored ads.
As our data was scraped from a list of unqualified websites, the data matching wasn’t likely to be perfect.
Experiments
Since I published that post, I have been experimenting a fair bit with list building, and have built up around 10 custom audience lists. I
‘ve uploaded a total of 48,857 Twitter usernames using this method, but only 29,260 were matched by Twitter (just less than 60% match rate).
From some other experiments where I have had better control over the input data, this match rate was between 70-80%.
Since we’ll be scraping Twitter directly, I expect our match rate to be much higher – 90%+
Finding Relevant Twitter Lists
So, we’re going to scrape Twitter, and the first step is to find Twitter lists that will contain users potentially interested in what we have to offer.
As an example, we’ll pretend we’re marketing a music website, and we’ve produced a survey we want to collect responses for.
An advanced Google query can give us lists of music bloggers: site:twitter.com inurl:lists inurl:members inurl:music “music blogger”
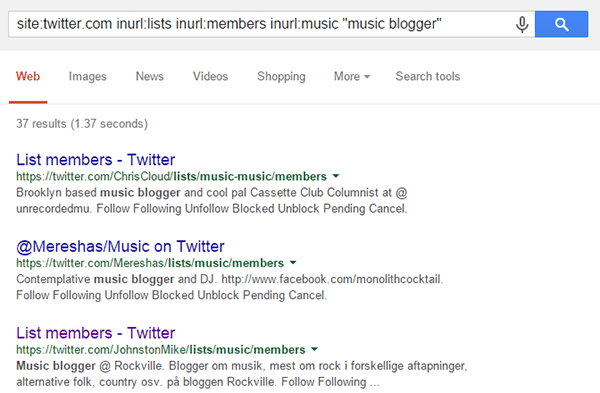 And a similar query can give us lists of music journalists:
And a similar query can give us lists of music journalists: 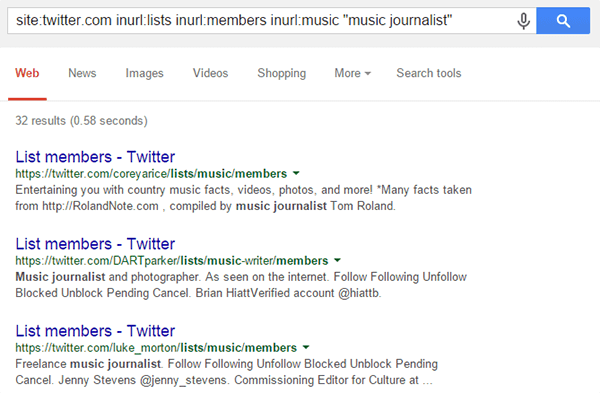 A really quick and easy way to scrape these Twitter URLs from the Google SERPs is to use a link copier extension like Linkclump.
A really quick and easy way to scrape these Twitter URLs from the Google SERPs is to use a link copier extension like Linkclump.
If you first set your Google results to display 100 results (here’s how), you can just copy them straight off the page.  Dragging this to the bottom of the results page will give us a list we can paste right into Excel:
Dragging this to the bottom of the results page will give us a list we can paste right into Excel: 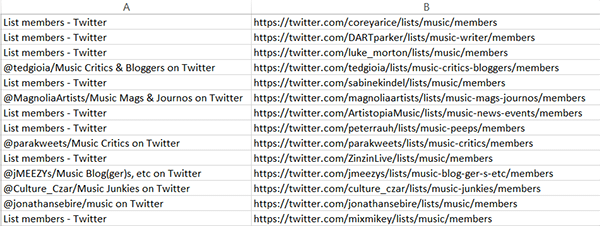 Any one of these pages shows us a load of Twitter users, editorially curated by someone else, specifically because they “think music is swell”.
Any one of these pages shows us a load of Twitter users, editorially curated by someone else, specifically because they “think music is swell”.
Swell.
Put Your Scraping Hat On
From the 2 Google queries we used, we have 66 Twitter lists we want to extract usernames from. We thought this would be a great advert for URL Profiler, which has a nice Custom Scraper function. But…it didn’t really work. Here’s what happened: First we uploaded the list of URLs into the white box, and hit ‘Custom Scraper (Beta)’ under ‘Content Analysis’. 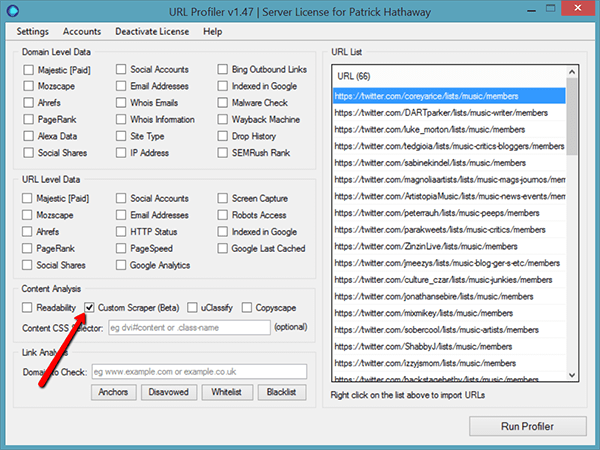 We wanted to scrape usernames from our list pages, as well as the number of members in each list. Using Inspect Element in Chrome, we pulled out the CSS selector we needed (more details on how to do this on this post).
We wanted to scrape usernames from our list pages, as well as the number of members in each list. Using Inspect Element in Chrome, we pulled out the CSS selector we needed (more details on how to do this on this post). 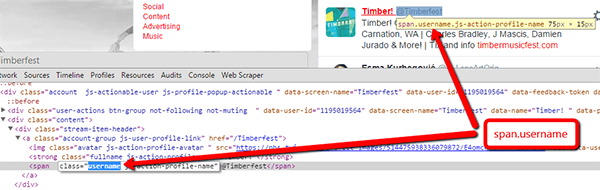 So we set up the tool to scrape the username as text from: span.username And similarly, the member number from: #page-container ul.stats li:nth-child(1) strong Which looks like this in URL Profiler:
So we set up the tool to scrape the username as text from: span.username And similarly, the member number from: #page-container ul.stats li:nth-child(1) strong Which looks like this in URL Profiler: 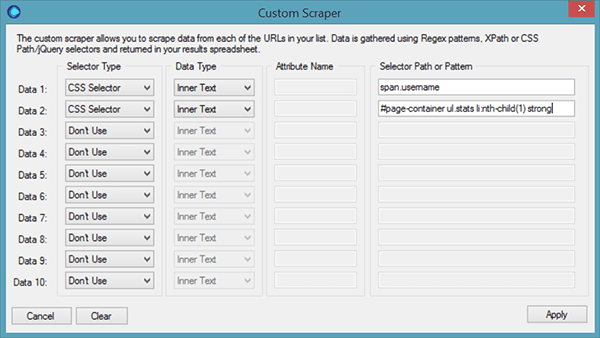 Then we just ran the profiler and waited for the results. And realised the problem…
Then we just ran the profiler and waited for the results. And realised the problem…
The Infinite Scroll Problem
Once we opened up the Excel output, we can found the data we were looking for under ‘Data 1’ and ‘Data 2’. 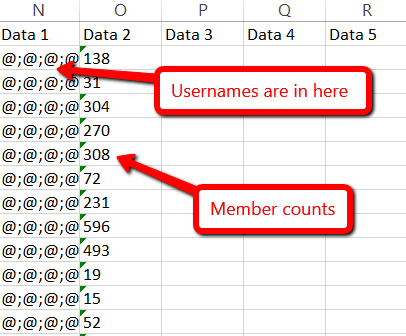 Although it looks a bit weird on the screenshot, the usernames are populated in that cell, separated by semi-colons. It is trivial to sanitise this data, just a bit of Excel data wrangling. Once we’d cleaned the data up, we saw that we hadn’t managed to scrape every username on the page. This is why:
Although it looks a bit weird on the screenshot, the usernames are populated in that cell, separated by semi-colons. It is trivial to sanitise this data, just a bit of Excel data wrangling. Once we’d cleaned the data up, we saw that we hadn’t managed to scrape every username on the page. This is why:  The custom scraper can’t currently process the infinite scroll to keep loading more usernames. In fact this is an issue most scraping software tools encounter, as sites auto-load the data in different ways.
The custom scraper can’t currently process the infinite scroll to keep loading more usernames. In fact this is an issue most scraping software tools encounter, as sites auto-load the data in different ways.
A Custom Solution (Free Tool Download)
Once we’d identified the problem, Gareth stopped what he was doing and spent a couple of hours knocking together a quick Twitter List scraper. Here’s how it works: 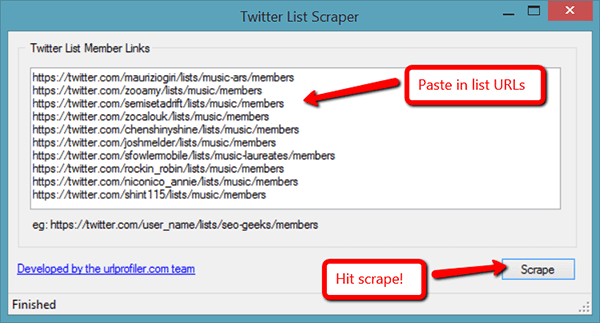 That’s all there is to it! Whereas the custom scraper can only currently grab the first 25 results or so (so we’d end up with 66 x 25 = 1650 usernames), this will get you the lot:
That’s all there is to it! Whereas the custom scraper can only currently grab the first 25 results or so (so we’d end up with 66 x 25 = 1650 usernames), this will get you the lot: 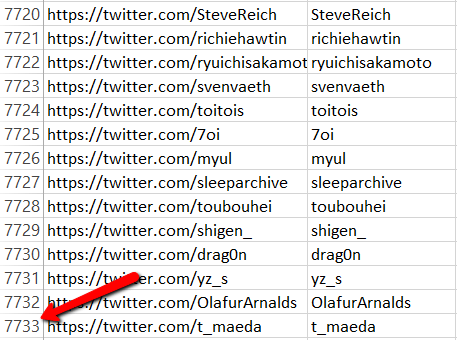 So in about 10 minutes total work, we have almost 8000 targeted Twitter usernames that we can advertise to.
So in about 10 minutes total work, we have almost 8000 targeted Twitter usernames that we can advertise to.
Download the Twitter Scraper Tool for Windows or Mac (completely free)
Twitter Custom Audiences
All we need to do now is upload this list as a custom audience on Twitter, then we can start serving ads to them.
I covered step-by-step instructions for this in my previous post, but the main thing to remember is to make all your usernames lowercase (just use =LOWER in Excel).
Then just head over to Twitter ads, go to Tools -> Audience Manager and hit ‘Create New List Audience’. You’ll end up on a page like this, where you need to select ‘Twitter usernames’ from the data type options.
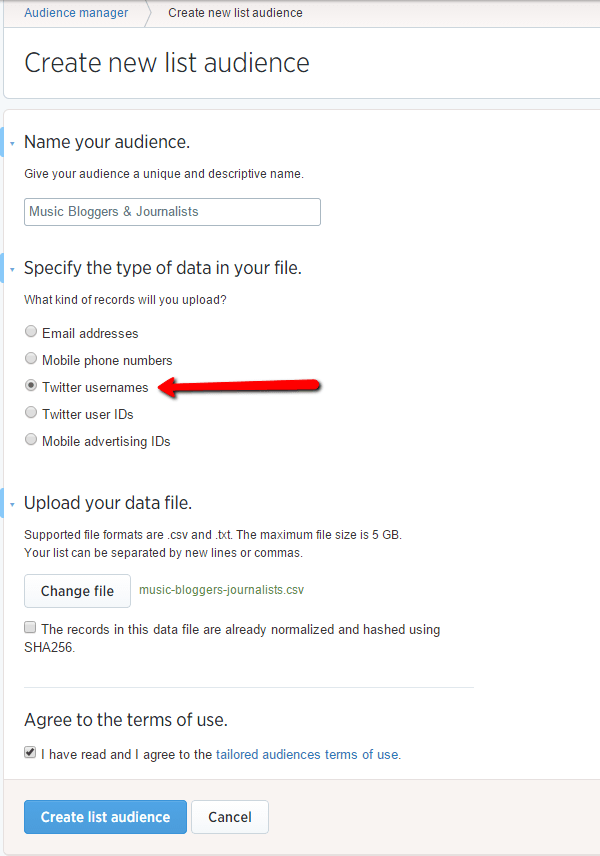
Before we started, I estimated that we could perhaps expect a 90%+ match rate on our upload. Well…not quite:
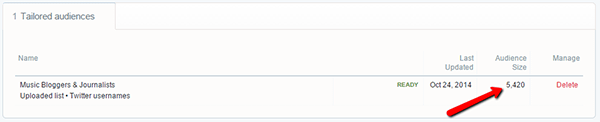
The matched audience size is 5430, out of an import of 7733 rows – just over 70%. This is clearly better than the ‘links’ method which had a match rate of 60%, but still not as high as I had hoped.
Possibly this is simply a result of the scale with which we are working. I’ll follow up on the blog when I’ve done more experiments.
Interest-based Segmentation
Twitter Lists are a very powerful (and often under-used) feature, as they form an interest-based segmentation of the Twitter user-base, created by users themselves.
This method allows you to tap into this segment and advertise to it directly for your own benefit. Download the Twitter List Scraper and get going today!
If you have any other ideas for ways to use the tool or build Twitter Custom Audience lists, please share them below.
Downloads
Without further ado, here are the download links for the Twitter List Scraper:

