Update 1.60 – Keyword Extraction & Improved Social Profile Scraping

Do you want the good news or the bad news?
Good news is we have a new update (woohoo!), bad news is that not a lot has changed (boo!).
We’ve had a recent issue with Majestic data not coming back correctly, so this is a release driven by necessity (to fix the problem), although we have added in a few improvements here and there for good measure.
Fixed: Majestic Data
As a number of you have noticed (and emailed me about), Majestic data has been going AWOL over the last few days. More specifically, 50% of the data has been going AWOL, and the rest has been mis-matched.
Technically speaking, something at Majestic’s end had changed or broken, meaning that the XML stream coming back from the endpoint was getting interrupted halfway, so if you requested data on 100 URLs you would only get data back for 50.
We switched to request the data in a different format, which has happily resolved the issue. So update now!
Improved: Social Account Scraping
We were challenged by one of our users that our social account scraper was missing some social profile URLs.
Gareth doesn’t take challenges lightly, so he fired up his laptop, got the fire burning, and poured himself a large glass of whisky warm milk, before hammering away at the code until he had social accounts coming out of his ears.
Literally.
And by literally, I mean figuratively.
He improved the detection algorithm, and increased the number of common pages searched, to find those slippery social account URLs.
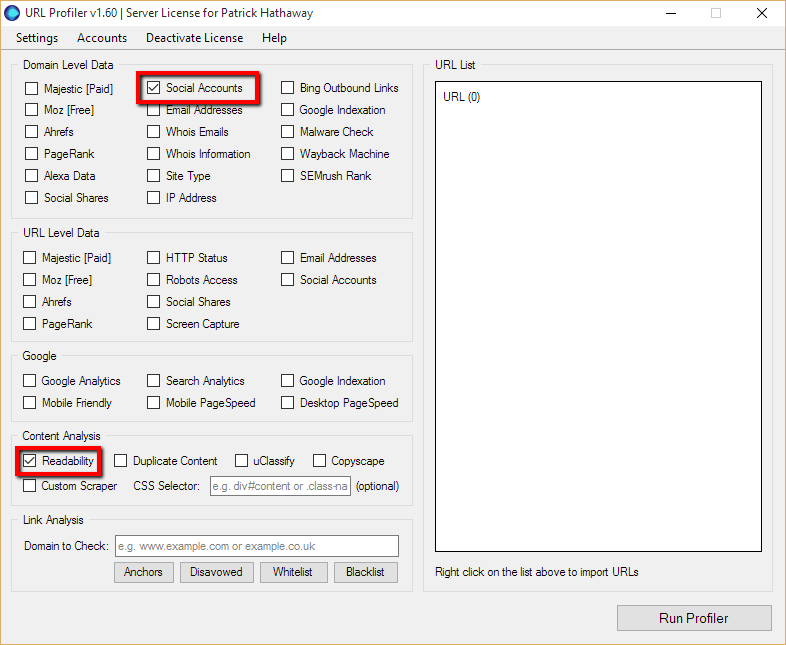
To sample this marvel, click ‘Social Accounts’ under ‘Domain Level Data’ (the top red box):
Improved: Keyword Extraction
To make the most of the image above, I have also red-boxed-ed ‘Readability’ under ‘Content Analysis’, wherein lies the next improvement in our release.
Readability is about as mis-named a misnomer as you can get, and it actually grabs allsorts of different data points, including:
- HTTP Status
- Titles and Descriptions
- Word Counts and Reading Time
- Content Reading Scores and Sentiment Scores
- Author names and links
- Common Keywords
It is the last bullet-point we have just improved – the keyword extraction. Previously this was a pretty basic list of top 5 words found on the page – kinda useful, but not really that informative.
Now, we have rebuilt the algorithm to better detect keyword pairs and remove more stop-words. As an example, here’s what we get from my post ‘Why SEOs Need To Care About User Experience‘
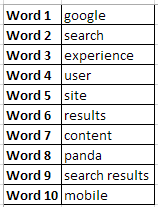
With just this word list, you don’t need to read the post the get an idea of what the article is about – and having written the post I can tell you that the words above act as a decent description of the post’s topic.
The idea of this feature is that it helps save time when you are auditing your site content.
Removed: Twitter Share Counts
So, as we announced recently, Twitter decided to close the API that powered share counts. You’ll have probably noticed the ‘Tweet’ buttons have all lost their precious share data.
![]()
You might have even read the post I wrote explaining why Twitter decided to remove share counts.
Either way, it’s happened now – Twitter went ahead and closed the API a couple of weeks back, so, in turn, we have stripped out the Twitter count feature from URL Profiler.
You can still grab share counts for Facebook, Google+, Pinterest and LinkedIn, though.
We also removed an unnecessary ‘error’ column from Search Analytics export (that is such a minor change it doesn’t warrant <h2> markup).
Downloads
Existing customers or existing trial users can grab the new update from here:
If you’ve not tried URL Profiler yet, you can start a free 14 day trial here. The trial is full featured, and you don’t need to give us any payment details to get started.