Introducing the Duplicate Content Checker

For almost as long as SEOs have cared about Google traffic, they have also cared about duplicate content.
Well before Panda came along, SEO professionals have fought to ensure their websites remain in Google’s good graces by avoiding duplicate content issues.
Checking Duplicate Content
The most common way to check if you have duplicate content indexed is to do the classic “search for some text on the page in quote marks”.
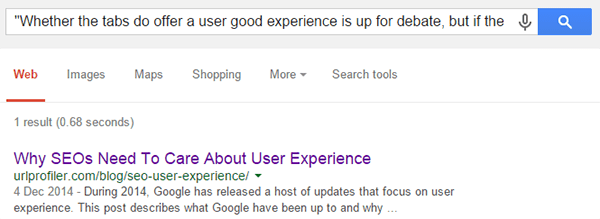
This is the sort of thing we want to see – just 1 result indexed.
But if you have hundreds of category pages or thousands of products, manually checking each one is not a realistic solution.
Up until now, bulk duplicate content checks have relied upon 3rd party databases with expensive APIs. The latest URL Profiler development allows you to instead check, en mass, against the one database you really care about – Google’s.
Karl Popper’s Black Swans
Before we go into the nitty gritty of how it works, a brief aside on scientific method. I imagine most SEOs, at some point or another, have tried to use the above “quotes” method to check if a site has a duplicate content issue by trying a few random URLs and seeing if they got any duplicate results.
You might try 10 URLs, see no duplicate results, and be reasonably satisfied there isn’t a duplicate content issue.
And maybe you’d be right – but not necessarily.
This is where Popper’s swans come in – he famously cited the example that ‘all swans are white’, which was largely believed by Europeans up until the end of the 17th century. For thousands of years, they’d only ever observed white swans rampaging around the local parkland.
Using inductive reasoning, they theorised that ‘all swans are white’.
However, when black swans were first discovered (in 1697), even a single observation completely undermined the theory that all swans are white – despite the millions of ‘positive’ observations that came before.
Our situation is somewhat different – in that a single page of duplicate content does not a ‘duplicate content problem’ make, but that isn’t the point. The point is that we should be trying to disprove the notion that a website doesn’t have duplicate content issues.
And we do that by increasing the number of observations we carry out.
Try harder.
Bulk Duplicate Content Checker
URL Profiler’s bulk duplicate content checker effectively scales out the “search in quotes” process across any list of URLs you import.
Here’s how it works:
- You enter the URLs you want to check – this can be a whole sitemap or simply a subfolder of URLs
- The software identifies the content area, then tries to find suitable snippets of text
- The software will take these snippets and search Google, using the quote marks method above
- It returns both the query used and the number of results found
As with our manual example above, you are really just looking for 1 result for each, implying yours is the only version indexed.
The Duplicate Content Checker In Action
In order to show the duplicate content checker in action, I picked a random ecommerce website called mytyres.co.uk (who sell car tyres). I deliberately picked a boring niche within the ecommerce space, as it is common to see a lot of duplicate content on sites like this.
Starting with a single URL, I pasted this into URL Profiler and ran it with the duplicate content check switched on; getting this result (click to enlarge):

The number indicates that there’s just a single result, and the fifth column (‘Duplicate Content URL 1’) shows that it was the input URL – a good result.
Columns 2 and 3 show the duplicate content snippets that were extracted from the page, and we can copy/paste the query URL into the browser to verify:
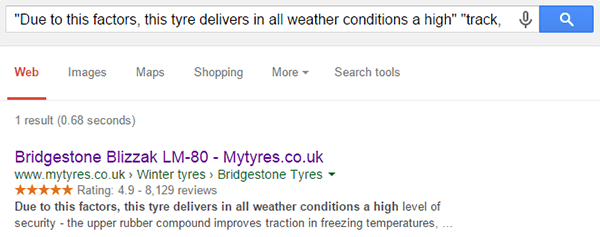
We can do a quick manual check to see where the text was taken from on the original page:

This shows how the tool works for a single URL, but we really want to do it in bulk.
Checking in Bulk
I’ll pick another tyre website – coopertire.co.uk (need to keep the American readers happy with their funny spellings…) and grab a load of product URLs.
Here’s what the tool looks like before you get going:
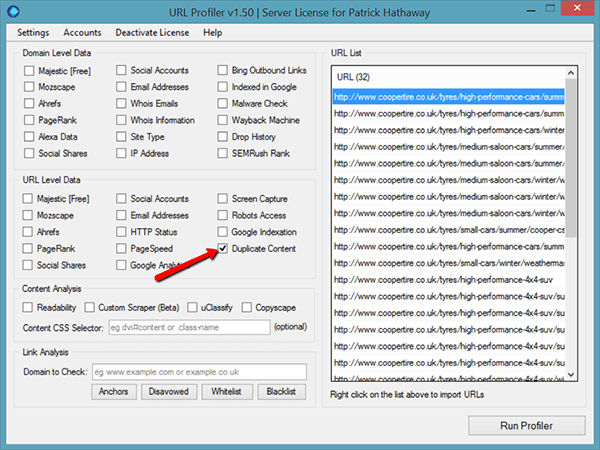
And once the tool’s finished doing it’s thang (sorry), we can see a range of juicy duplicate content issues.

Copying the ‘Duplicate Content Results’ URL into your browser will show you the Google query used, so you can manually spot check results. Let’s try one out for size:
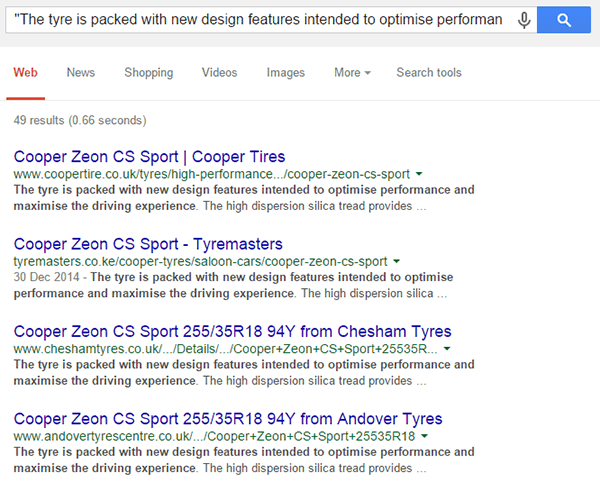
Yikes! Manufacturer’s description anyone?
The use of the duplicate content checker would allow you to audit this type of situation more comprehensively – so you can pick apart the pages and start planning a content production/rewrite strategy for all affected pages.
Also notice we had a result saying ‘Thin Content’. That basically means that the software has not found any sufficiently long paragraphs on the page to get meaningful results. Here’s an example of one it found:
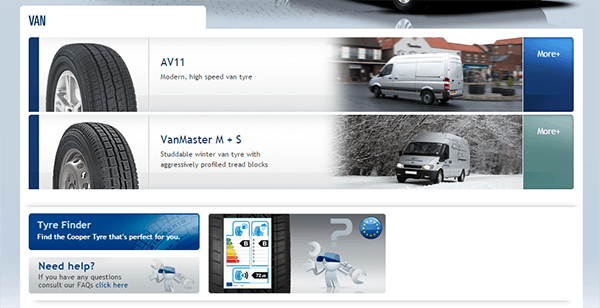 That’s literally all we’ve got to work with. Thin content? Touché.
That’s literally all we’ve got to work with. Thin content? Touché.
Increase Accuracy By Selecting Content Areas
Duplicate content is normal. Practically every website on the internet will have some duplicate content somewhere – a returns policy, delivery information, or even just an address.
This isn’t the stuff we should be worried about, as Google is not going to penalise you for ‘normal’ duplicate content.
So we really want to exclude this stuff, and only check the content areas that we expect (or hope!) to be unique in the first place.
We can do this using one of the settings in the duplicate content checker, by setting the CSS selector that defines the content area you wish to analyse.
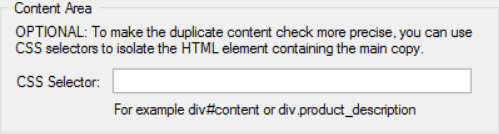
Check out the tutorial for a more comprehensive breakdown on how to use this, but I’ll show a quick example here.
All we need to do is bring up one of the pages we are profiling, highlight some of the content then right click in the browser and choose ‘Inspect Element’ from Chrome’s options.
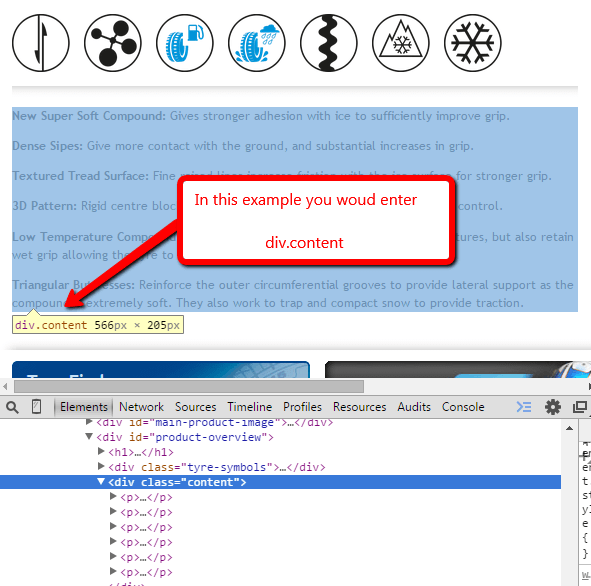
The opens Chrome’s DevTools at the bottom of the screen, where we can locate the div which highlights the full content area, then the yellow bubble will tell us what the CSS selector should be (in this case, it is ‘div.content’).
This allows us to hone in on the important area, so the tool won’t get distracted by any boilerplate copy on the pages.
When using this feature, it is sensible to group up the pages you are profiling to make sure they all have the same page template (and therefore the same content area) – for example you might group all ‘product pages’ and scan them separately to category or subcategory pages.
Internal & External Duplicate Content
The default setting in the Duplicate Content Checker will look for any duplicate content it finds – which could of course include results from your own website.
However they should really be considered different beasts:
- External duplicate content could indicate you have a big problem with content scrapers, or you’ve taken all your content from a manufacturer’s portal
- Internal duplicate content could mean you have a lot of copy/paste descriptions or boilerplate content everywhere
URL Profiler allows you to choose from: all duplicate content, internal duplicate content, or external duplicate content – so you can deal with each issue in turn.
So…You’re Gonna Need Some Proxies (Yes Proxies)
To the uninitiated, you can’t go around scraping Google’s results without them having something to say about it. If you try and use this feature without proxies, don’t expect your colleagues to buy you a pint later after they’ve spent all afternoon filling out CAPTCHAs.
That’s where the proxies come in.
Don’t worry, I’m not going to go all black hat on you.
Erm…
Wait! We’re not talking about firing up SEnuke or GSA – we’re doing site audits here, this is a hat-agnostic endeavour.
We recommend a provider called BuyProxies.org, and we suggest you use their Dedicated Proxies. We have written a full, detailed guide which explains exactly how to use proxies with URL Profiler and how to get set up with BuyProxies.org.
How many you get depends on how fast you want the results (see the tutorial for a speed guide), but you can get 10 for $20 a month (around 14 quid).
If you think that sounds expensive, then just consider Copyscape charge $0.05 per lookup, that’s $50 for 1000 lookups. And you only get to to search the Copyscape database.
By contrast, with a set of only 10 private proxies you could scan 1000 URLs in around half an hour. Then you could use them again. And again. And again (you get the idea).
If fact you can use them every day, and do all your duplicate content checks and indexation checks with the same ones.
You know it makes sense.
Finally – a Method For Identifying Duplicate Indexed Content in Bulk
While testing this new release, I carried out a thorough content audit for a client. I’d already identified in an initial audit that they’d been soundly thrashed by Panda on numerous occasions, so I combed through some 16,000 pages hoping to identify all the bamboo.
Using URL Profiler, in a total of about 10 hours work, I was able to identify:
- 54 key pages with significant external duplicate content, which required a complete rewrite
- 510 pages with internal duplicate content – much of which were product pages and review pages that could be consolidated
- 7951 thin pages that contributed nothing, and could be deindexed
- 7263 pages which were fine and they could leave as they are
Granted, I also used the Google Analytics integration and the Google Index Checker to help pick apart the wheat from the chaff, but the duplicate content checker was absolutely invaluable for identifying the problem pages.
Don’t leave home without it (and watch out for them blasted swans! They can break a man’s arm don’t you know?)