So You Think All Your Pages Are Indexed By Google? Think Again

It is not uncommon for SEOs to disagree on the KPIs you should track to measure your SEO efforts.
One metric which is hard to argue with, however, is indexation. If a page is not indexed, it has vlno chance of attracting traffic from search.
We have recently found that the classic method of checking indexation (using the info: command) gives false positives, which in turn can lead to inaccurate conclusions about indexation and site health.
What Do We Mean By Indexation?
As Google crawls the web, they build a repository of the webpages they find, and from this repository they generate their ‘index’.
For each webpage crawled, Google parses the document, splitting it out into a set of word occurrences (along with additional information).
At the same time, they parse out all the links and store information about them such as anchor text and where the link points to.
Google takes the parsed data, and generates an inverted index, assigning the webpage document against each of the words on the page; this is what allows them to search their index so quickly.
If this sounds familiar, that’s because it is.

The link data is also indexed, which is what allows them to compute PageRank and other quality scores. When Google process a searcher’s query, they search their index to find documents that contain the words searched, then order the results in terms of relevance to the query.
In short, if a webpage has been indexed, it is ‘findable’ (as in, it is a viable search result for a relevant query).
Index Check
Google has told us for years that the way to check index status of any URL is to use the info: operator.
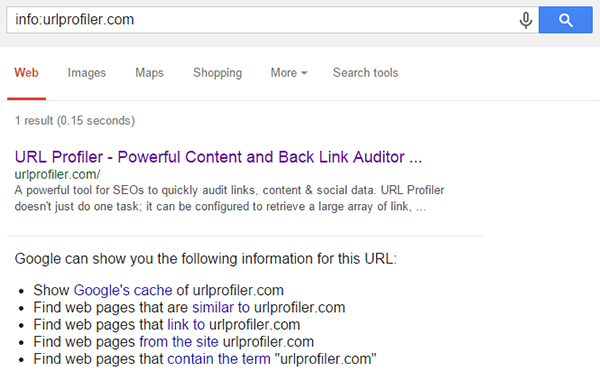
Matt Cutts always told us to do it this way (here’s an example from almost 10 years ago), and John Mueller said the same thing just a few weeks ago:

URL Profiler’s index checker uses this info: command, as does Scrapebox – so both allow you to check index status in bulk.
Thus, if a webpage comes up using the info: command, it is indexed, and therefore potentially findable.
Or so we thought…
Testing The Theory
On building our latest release of URL Profiler, we were testing the Google index checker function to make sure it is all still working properly. We found some spurious results, so decided to dig a little deeper. What follows is a brief analysis of indexation levels for this site, urlprofiler.com.
Checking Indexation Levels
We wanted to find out exactly how many of our URLs are in Google’s index.
First stop, we’ll look at a site search on Google (The -inurl:support command simply removes our support subdomain which we’re not interested in):
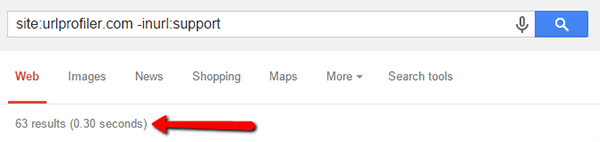
This sounds about right. We can also compare to Google Webmaster Tools index status:
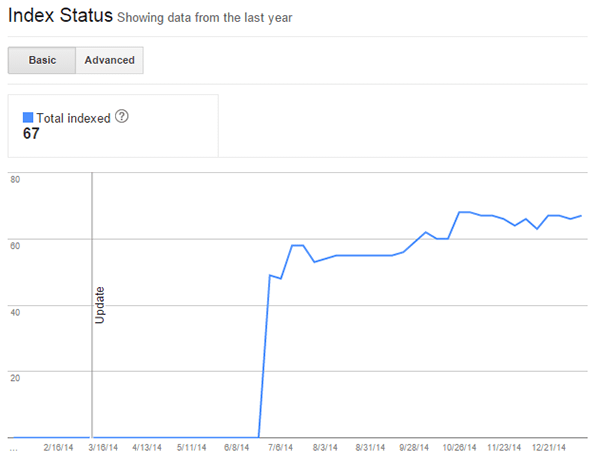
Considering that the site: search command isn’t super reliable, it is a good sign that these figures roughly match up.
We get a different story, however, when we look at the sitemap data in Google Webmaster Tools:

That seems weird, particularly since the figure of 63 matches up exactly with what we saw in the site search. This poses 2 important questions:
- Are there URLs in the Google index which are not in the sitemap?
- Is the sitemap data in GWT just completely inaccurate?
When trying to answer these questions, there is little more we can learn by looking at total indexation levels, instead we’ll need to look at individual URLs.
Checking Indexation In Bulk
We could, of course, check each individual URL manually, one-by-one. But who wants to do that?
As I mentioned above, we can check index status in bulk using URL Profiler (which happens to use the info: operator to do this)
So, to do this we’ll import our sitemap and check the tickbox for ‘Indexed in Google’ under URL Level Data.
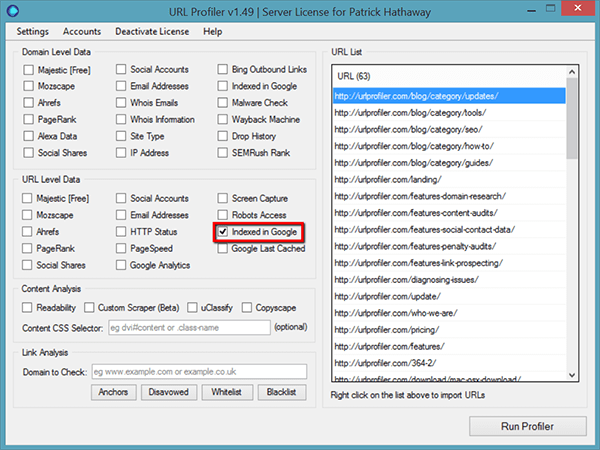
The software will warn you to use proxies, with very good reason – you will either get your IP blocked by Google and/or you will get some very weird and totally unreliable results.
The raw data results look like this:

Every single URL on my list was given a ‘Yes’ response. This implies that every single URL from our sitemap is indexed, and sitemap data in GWT is just plain wrong.
We’ll come back to the sitemap issue further on, and instead try to deal with our first question…
- Are there URLs in the Google index which are not in the sitemap?
Let’s Scrape Google and Find Out
If you’ve not seen it already, we have a little free tools area which includes a tool for scraping Google’s results, called the Simple SERP Scraper.
We can load in our original site search query and send it off to scrape the SERPs:
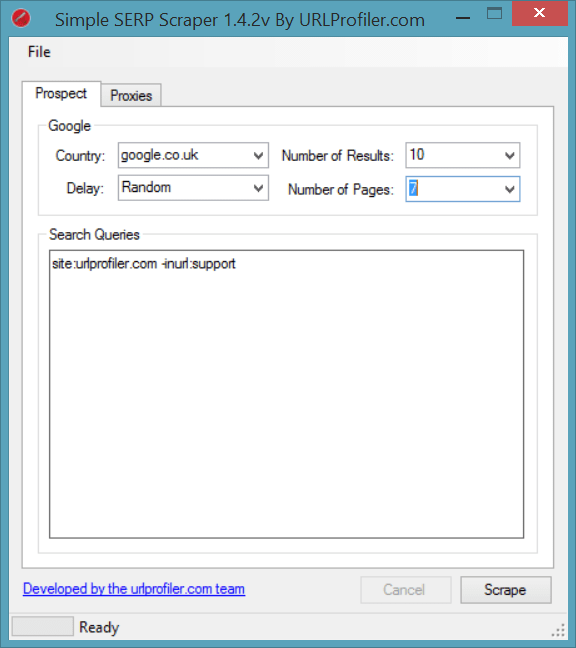
Again, you’ll need proxies if you are scraping loads of results, but we can get away with no proxies and the ‘Random’ delay feature since we aren’t after too many results.
The results come out like this, and ours go from position 1 to 63 as expected:

To compare these results to our sitemap, we just need to copy the scrape results and paste these into another worksheet alongside our URL Profiler results from earlier, then just use a nested VLOOKUP:
=IFERROR(VLOOKUP(A2,’URL Profiler Results’!A:A,1,FALSE),”Not in Sitemap”)
By the way, if you need any help with VLOOKUP, please check out this excellent guide.
This shows us that 59 match up perfectly, yet there are 4 rogue ‘extra’ pages. The URLs are too long to display, so I’ve added a notes column for clarity:

Nothing too concerning there, just a bit of housekeeping for us to sort out. It does however help us answer our first question:
- Are there URLs in the Google index which are not in the sitemap?
Not really, no. There are a sum total of 4, half of which will probably drop out at some point. Certainly nothing to explain the 50% sitemap irregularity.
Comparing To The Sitemap
Above, we compared the search results to our sitemap data. To check if the sitemap data is accurate, we will need to do the inverse VLOOKUP:
=IFERROR(VLOOKUP(B2,’Scrape Results’!A:A,1,FALSE),”Not In Search Results”)
This compares the sitemap data to the search results.
As I’d expected, most of the results did match up to the sitemap. However, there were 2 that didn’t:

But there were 61 that did match, meaning Google’s claim that only 33 were indexed out of the 63 we submitted is total bullshit.
2. Is the sitemap data in GWT just completely inaccurate?
Yes. At least it seems to be for this specific test case.
The Difference Between Indexed and Findable
Look at the last table above. We had bulk checked indexation on each page (using URL Profiler), and all of them were apparently indexed.
Yet the top 2 did not appear in the search results under the site: operator.
We’d better examine the 2 URLs in question, as below (you’ll see the sort of shit that can get indexed if you’re not careful):
Page 1: https://172-233-222-199.ip.linodeusercontent.com/update/
This is a page necessary for our update links, but not one for users to see. There is a grand total of nothing on it.
It’s actually even blocked in our robots.txt file. Quite why it’s in our sitemap then…
Page 2: https://172-233-222-199.ip.linodeusercontent.com/documentation/getting-started/installing/
I don’t even know why this pages exists. There’s nothing on it. At all.
These pages are quite simply… shit.
Are They Indexed Or Not?
I can totally understand why Google would not want these pages in their index. There’s basically no content on either of them – never mind unique content.
But when we checked with URL Profiler, we found that they were indexed. As mentioned earlier, the checks URL Profiler performs are based on the info: operator, which we can also use manually to confirm:
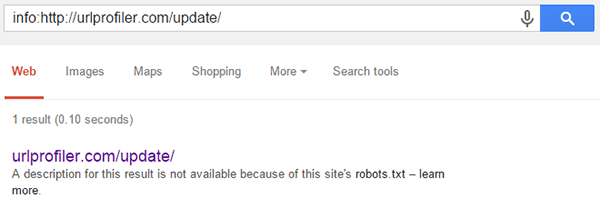
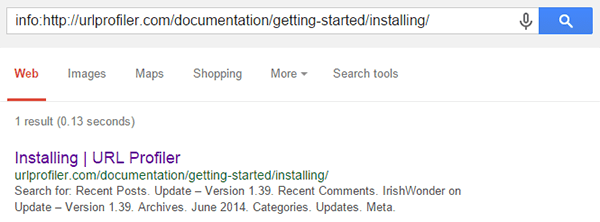
But we can also try some other methods to check if the URL is indexed. Considering first the update page, we can test out the site: operator;
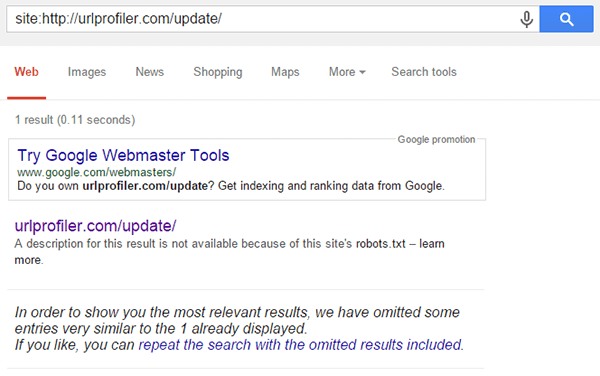
This shows that, although the page wasn’t listed in the general site: search, Google will display it when queried directly like this. They also offer us to ‘repeat the search with the omitted results included’, which yields the following:
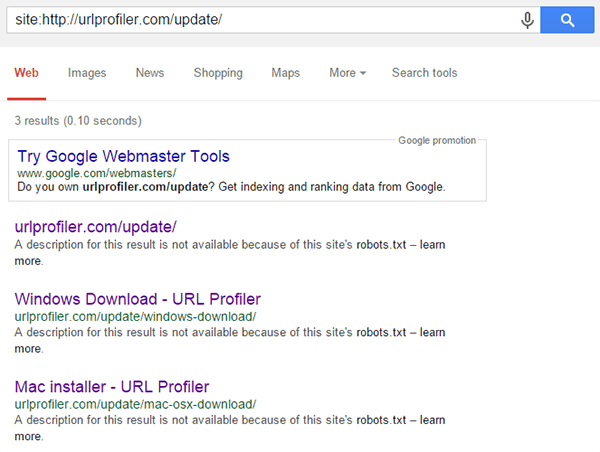
These are 2 more results, neither of which were in the general site: search nor in the sitemap, yet are clearly still indexed and accessible when queried directly.
So we can also try the same search on our other rogue URL, the documentation one:
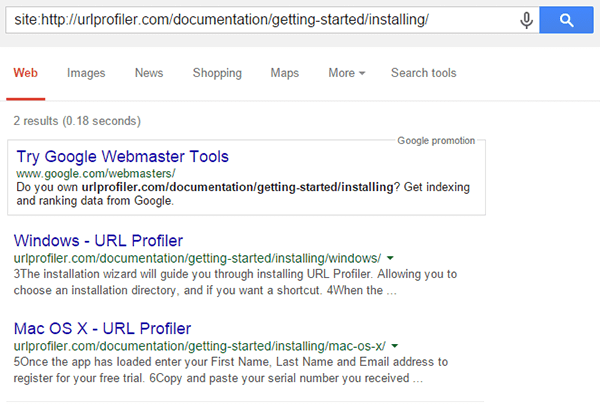
This shows similar URLs – with the same path – but not the actual URL we were looking for. Even when queried directly, Google will not display the URL.
Unless, of course, you do an info: request.
These pages clearly are indexed to some degree, but unless you really push Google to show them to you, they aren’t going to do it.
Not Findable
Whilst these webpages are indexed, they are not findable – at least not for any normal searcher. And that is what we really mean when we’re checking index status: ‘can searchers find my stuff?‘
On it’s own, the info: command is not a sufficient check.
If a webpage is returned under the info: command, this does not necessarily mean it is findable.
An Example Beyond Our Tiny Little Website
Maybe this post should have started with the caveat that we’ve only done it on our site, which is very small. BUT it is only by using such a small site that we were able to get definitive answers on some of the questions we asked.
If you have a site with several thousand pages or more, there is no way you’ll be able to scrape Google to check what has been indexed. The test above shows a proof of concept, and demonstrates that our original theory (that we have been relying on for years as accurate) is inherently flawed.
So here’s an example from a larger site – dundee.com. The Hit Reach gang and I publicly audited this site last year, pointing out a myriad of Panda problems (surprise surprise, they haven’t been fixed).
Here’s one of the pages we’d found issue with:
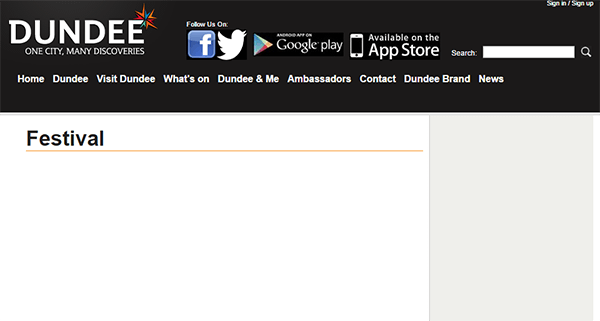
Can you guess why?
Google have it ‘indexed’ using the info: command:
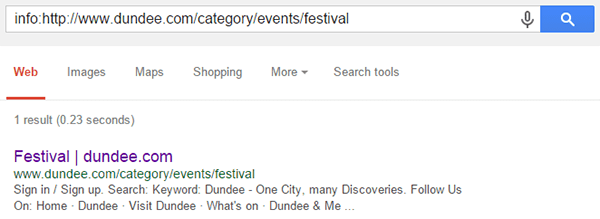
However, we want to know if it is ‘findable’ – could it be found searching the URL, or a site search for the specific URL?
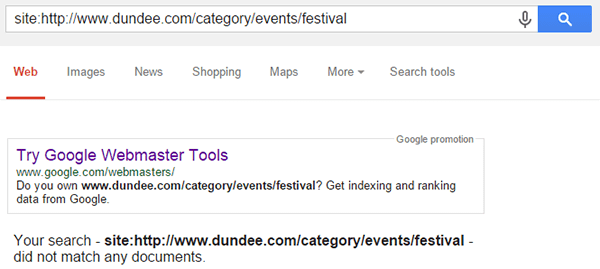
Nope.
The info: command has effectively sold us a red herring. This check would have fooled us into thinking that the URL is ‘properly indexed’ (i.e. findable).
Just ‘being in the index’ doesn’t mean shit if no one can find you.
Is This Just The Old Supplemental Index?
No, it’s nothing like it. The supplemental index was simply a second index tier, which was crawled and queried on a lower priority to the main index.
Google have publicly stated that they maintain several index tiers which work in this manner. What we are seeing here is completely different – it’s an index tier full of absolute shit.
So far we’ve seen it can include:
- Omitted results pages
- Pages blocked by robots.txt
- Thin pages
- Orphan pages
- Non-unique pages
Possibly this is Google just cleaning up the index so site owners don’t have to. It certainly seems that way based on this response from John Mueller in a Google Webmaster Hangout last year (watch til about 38:30):
Note: To clarify, the site owner in question here was saying 90% of his site was now being displayed under ‘omitted results’ (which he was calling the supplemental index).
John clearly states that Google have decided to filter this stuff out, for one reason or another.
This basically means that, although Google knows about these pages, they’re never going to give you any search traffic.
I don’t know about you, but I most certainly wouldn’t want to see a significant number of my pages ending up in this shit repository.
Where Does Caching Fit In?
Another datapoint we can get back from Google is the last cache date, which in most cases can be used as a proxy for last crawl date (Google’s last cache date shows the last time they requested the page, even if they were served a 304 (Not-modified) response by the server).
 The little green arrow alongside the URL allows you to access the cached version of the page.
The little green arrow alongside the URL allows you to access the cached version of the page.

URL Profiler also has the option to bulk check cache date. When we do that on the URL Profiler sitemap we actually see even more dodgy URLs we need to fix:

There’s 7 URLs that Google have decided not to cache. Some of these we saw earlier, and 1 is disallowed in robots.txt, but none of them are set to noarchive.
For brevity, I won’t screenshot each of these for you (*ahem* URL Profiler does have a bulk screenshot function though…) – take it from me that they are also very poor, thin pages with little to no unique content on any of them.
Google’s cache is primarily a user feature, allowing users to access content when the website itself might be down. It makes perfect sense that Google would not want to cache results they don’t believe offer the user any value.
This also fits with John Mueller’s explanation in the video above – the ‘omitted results’ pages also always appear to not be cached – if you believe a page offers no additional value to the searcher, why would you store a copy of it?
Similar to what we saw with the the index check, pages not cached appears to be an indicator of poor quality.
We Need To Do Better Than This
We have already seen how inaccurate Google Webmaster Tools data can be – and even if it is accurate, a single figure alone only tells you how many URLs have been indexed, not which ones.
Bulk checking indexation can help illuminate the real situation, but we’ve been doing it wrong.
Imagine you were auditing a site and you wanted to know which of their 20,000 URLs were indexed. You could check all of these with the info: command, and for all you know every single one of them could be in the shit repository.
Using something like URL Profiler or Scrapebox to bulk check index status will give you inaccurate results, which could lead you to make false conclusions about the state of the website.
We need something better.
So, We Built It
The latest release of URL Profiler, version 1.50, features an improved Google index checker, implementing everything we learnt above. You can read more about the update here (and also read about our other cool new feature, the duplicate content checker).
Our new indexation check offers more than a simple Yes/No, this is a sample output:

This is what we now show you:
- Google Indexed: Can we find the URL in the base index? As in, does it display for a search of the URL? In some cases an alternative URL is present instead, so we return ‘Alternative URL’ as the result. All other results are Yes or No.
- Google Info: Indexed: We only check this if the URL is not in the base index (i.e. did not get a ‘Yes’ in the first column). Otherwise will display Yes/No/Alternative URL as above.
- Google Index: Based on the checks, we determine if the URL is in the base index, or if it is in the ‘Deep’ index (the ‘shit repository’), or if it is not indexed at all. Note that if we find an Alternative URL in both checks, the specific URL you requested is listed as not indexed.
- Google Indexed Alternative URL: If we found an alternative URL indexed instead of the one we searched for, we display this here.
- Google Cache Date: Simply displays the last cache date for each URL. If there is no cache date, the result is listed as ‘Not Cached’. On occasion we are unable to check the cache date, in which case the message ‘Check Failed’ is displayed instead.
We have found alternative URLs typically come up in a canonical situation. For example you query the URL example.com/product1/product1-red, but this URL is not indexed, instead the canonical URL example.com/product1 is indexed.
Note: If you haven’t realised yet, yes this feature does rely on proxies. More information about them on our duplicate content checker tutorial.
How To Use This Data
If you are at all concerned about URL indexation for your site, the only way to really know if all your URLs are indexed is to check them all.
Here is a straightforward workflow you could use:
- Crawl your site using Screaming Frog
- Use the ‘Import from Screaming Frog‘ feature to import your URLs to URL Profiler
- Run an indexation check on all the URLs, and also optionally pull back GA data and link metrics
This will give you a much more comprehensive audit document in order to make SEO recommendations and fixes (by the way we also have a full tutorial on the indexation checker).
If you’re not concerned about URL indexation, don’t you think you should be?